
Message Prioritization in Apache Kafka

Why Do We Need Message Prioritization?
In many traditional messaging systems like JMS or AMQP, messages can carry a priority so that critical ones are processed first.
Examples:
A call center resolves severe complaints before minor issues.
An airline serves premium passengers before economy.
A telecom company offers loyalty benefits to VIPs first.
In simple terms: Message prioritization = ensuring important messages are processed before less important ones.
Naturally, developers wonder: “Can Kafka do this?”
Short answer: No, not natively.
Why?
Because Kafka isn’t a traditional messaging system—it’s an event streaming platform.
That distinction matters. Kafka focuses on high-throughput, ordered, durable event logs, not reordering messages by priority.
But here’s the good news: While Kafka doesn’t provide prioritization out of box, we can design practical patterns to achieve similar effect.
Why Doesn’t Kafka Support Prioritization?
Apache Kafka is not a traditional messaging queue—it’s an event streaming platform. That distinction explains why prioritization doesn’t exist natively.
Commit Log: The Immutable Backbone
At its core, Kafka is built on a commit log:
A log is like a journal—events are appended strictly in order they occur.
Each record has an immutable offset.
Records cannot be modified or reordered.
If Kafka allowed reordering by priority, log would no longer reflect true sequence of events.
👉 This would break fundamental patterns like event sourcing and CQRS, which rely on event order being an accurate representation of history.
Consumers: Who Owns the Order?
In traditional systems (e.g., JMS with
JMSPriority), broker reorders messages before delivery.Kafka works differently:
Broker never reorders events—it only appends them.
Consumers decide how to interpret or prioritize processing.
This approach makes Kafka scalable, consistent and fair—all consumers see the same ordered log. But it also means there’s no built-in priority queue behavior.
The Key Takeaway
Kafka is designed for high-throughput event streaming, not dynamic message shuffling.
Expecting features like prioritization from Kafka is a mismatch—yet its immutable log is exactly what makes it reliable for distributed architectures.
Understanding Partitions and Consumer Groups
To understand why prioritization is tricky in Kafka, you first need to know two core concepts: partitions and consumer groups.
Partitions
A topic (e.g.,
orders) is split into partitions.Partitions are distributed across brokers for scalability and fault tolerance.
Messages inside a partition are strictly ordered, but not across partitions.
⇒ This design gives Kafka high throughput and parallelism—but it also means:
👉🏻 To “reorder” messages by priority across partitions, you’d need to collect, merge, and sort them → complex and inefficient.
Consumer Groups
A consumer group is a set of consumers that share the work of reading a topic.
Each consumer in the group gets messages from different partitions.
Groups make Kafka scalable under high load, but…
Consumers work independently.
There’s no built-in notion of priority.
Why Prioritization is Hard
Messages are immutable (can’t be reordered).
Messages are spread across partitions.
Multiple consumers process different partitions in parallel.
📌 Bottom line
Kafka’s partition + consumer group model is brilliant for scalability and resilience but it makes native message prioritization impractical.
The “Bucket Priority Pattern” – A Workaround
Since Kafka doesn’t support message prioritization out of box, we can simulate it using the Bucket Priority Pattern.
The Idea
Instead of re-sorting messages later, we group them into priority buckets at the producer side.
Bucket = a set of partitions.
Example:
Platinum bucket → urgent, high-priority orders.
Gold bucket → normal, lower-priority orders.
Consumers don’t need to sort—they simply read from their assigned bucket.
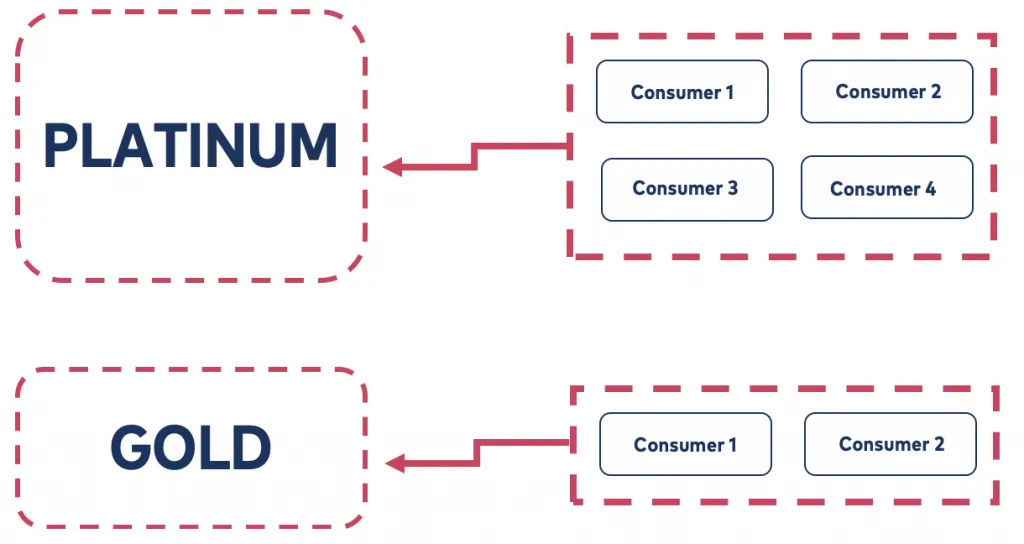
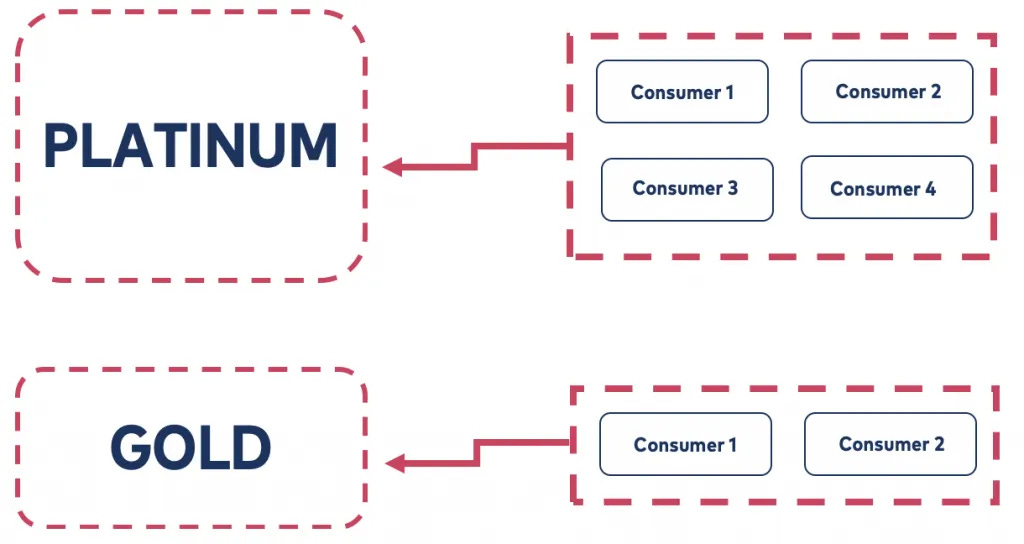
How Buckets Work
Producer chooses the bucket
Based on the message key (
"Platinum-order-123").A custom partitioner ensures record goes into right partitions.
Consumer reads its bucket
A custom assignor ensures consumer gets only partitions for its bucket.
Bucket size = share of partitions
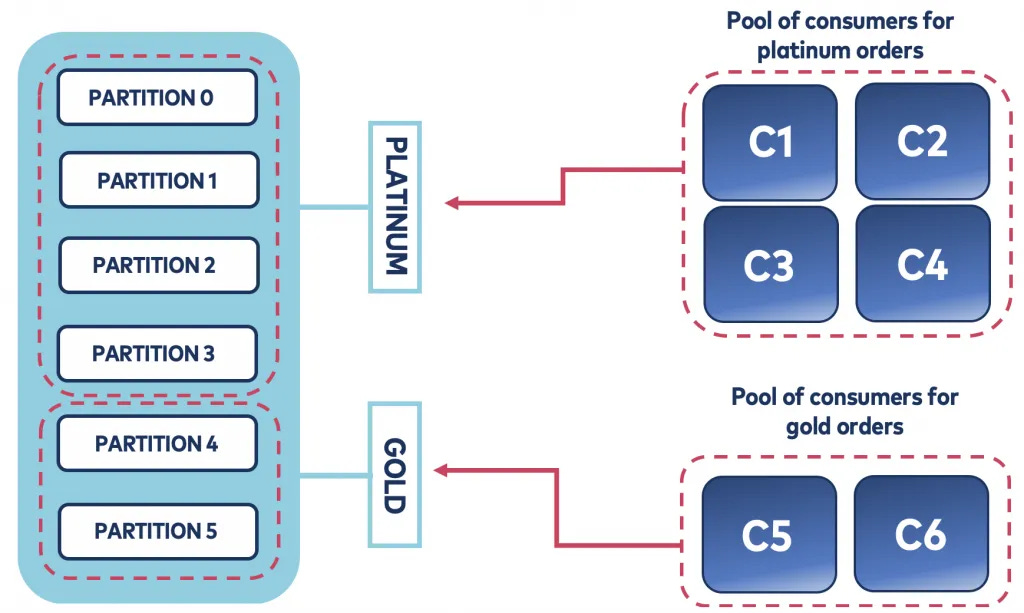
Example: Topic with 6 partitions:
Platinum = 70% (4 partitions).
Gold = 30% (2 partitions).
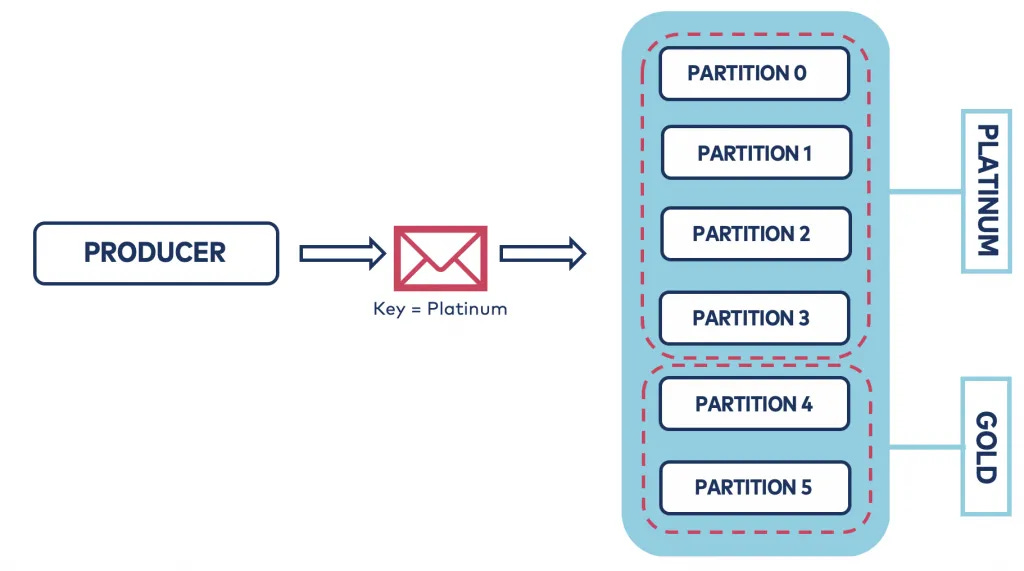
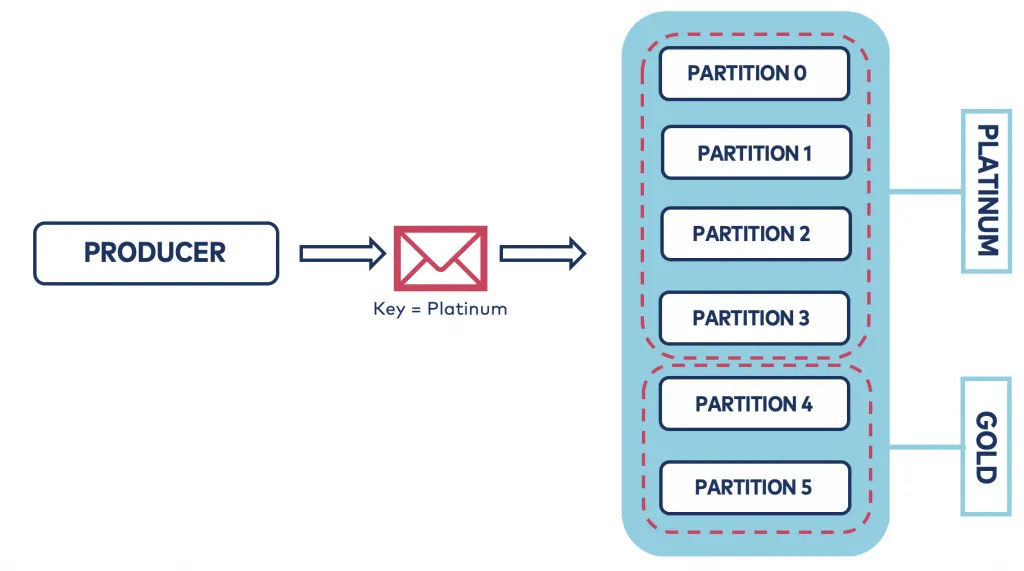
Example: Orders System
Producer
Platinum orders → partitions 0–3.
Gold orders → partitions 4–5.
Consumers
Platinum consumers → read only partitions 0–3.
Gold consumers → read only partitions 4–5.
✅ Result: Platinum messages are processed first and faster (more partitions + more consumers).
Implementation
Producer Configuration
Use a custom partitioner (
BucketPriorityPartitioner):
configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, BucketPriorityPartitioner.class.getName());
configs.put(BucketPriorityConfig.TOPIC_CONFIG, "orders-per-bucket");
configs.put(BucketPriorityConfig.BUCKETS_CONFIG, "Platinum, Gold");
configs.put(BucketPriorityConfig.ALLOCATION_CONFIG, "70%, 30%");
producer = new KafkaProducer<>(configs);
👉 Topic =
orders-per-bucket👉 Buckets = Platinum (70%), Gold (30%)
Producer Code Example
for (;;) {
int value = counter.incrementAndGet();
String recordKey = "Platinum-" + value;
ProducerRecord<String, String> record = new ProducerRecord<>("orders-per-bucket", recordKey, "Value");
producer.send(record, (metadata, exception) -> {
System.out.printf("Key '%s' sent to partition %d%n", recordKey, metadata.partition());
});
Thread.sleep(1000);
}
Keys starting with
"Platinum-"→ Platinum partitions.Keys starting with
"Gold-"→ Gold partitions.
Consumer Configuration
Use a custom assignor (
BucketPriorityAssignor):
configs.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, BucketPriorityAssignor.class.getName());
configs.put(BucketPriorityConfig.TOPIC_CONFIG, "orders-per-bucket");
configs.put(BucketPriorityConfig.BUCKETS_CONFIG, "Platinum, Gold");
configs.put(BucketPriorityConfig.ALLOCATION_CONFIG, "70%, 30%");
configs.put(BucketPriorityConfig.BUCKET_CONFIG, "Platinum");
consumer = new KafkaConsumer<>(configs);
👉 This ensures consumer only reads from Platinum bucket.
Consumer Code Example
consumer.subscribe(Arrays.asList("orders-per-bucket"));
for (;;) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(Integer.MAX_VALUE));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("[%s] Key = %s, Partition = %d%n", threadName, record.key(), record.partition());
}
}
Consumers fetch only the partitions from their bucket.
Multiple consumers can share the load within a bucket.
📌 Summary ⇒ Bucket Priority Pattern shifts prioritization from sorting later to bucketing upfront.
Producers decide the bucket.
Consumers stick to their bucket.
High-priority buckets get more partitions and more consumers → faster processing.
Key Takeaways
Kafka doesn’t support message prioritization natively because of its commit log architecture.
You can achieve “good enough” prioritization using the Bucket Priority Pattern.
This involves:
Producer-side bucketing (via custom partitioner).
Consumer-side filtering (via custom assignor).
Partition allocation by percentage for priority levels.
Result: High-priority messages get more partitions + more consumers → processed faster.
Conclusion
Message prioritization is a common requirement but doesn’t fit naturally with Kafka’s design.
The Bucket Priority Pattern provides a practical workaround:
Separate high- and low-priority messages at the producer level.
Assign consumers to the right bucket.
Scale buckets differently based on business needs.
This approach respects Kafka’s design principles while still letting you handle urgent messages first.